
Back
The CI process at PicScout
June 22, 2014
We’ve been using Jenkins as our build server for some time now, but recent switch from TFS to Git allowed us, among other things, to implement a more sophisticated approach to Continuous Integration process.
We’ve already had all CI principles covered before – single branch everyone was working and committing to on a (almost) daily basis, automated self-testing builds etc. But if you look at the definition of CI in Wikipedia, it says that in CI “no errors can arise without developers noticing them and correcting them immediately”. Unfortunately this was not our case.
But first of all, why errors resulting in a broken build are such an issue ? Because it impacts entire team, anyone “getting latest” is likely to encounter issues at some stage because of the errors introduced by someone else and it may take a lot of time to realize that it’s not your fault after all. And a check-in on a broken build makes things even worse. In addition, you are not guaranteed to have a stable version for deployment.
Why did it happen for us ?
A little bit of background to start with – we have one job (build in Jenkins) per solution, and we have dependencies set up between jobs to reflect dependencies between projects in separate solutions. Whenever job is run successfully, it will trigger its dependent jobs, so a check-in may actually result in multiple Jenkins jobs running in chain one after another. The whole process used to take more than 30 minutes, with developers waiting all this time for possible error notifications whereas the source was being dirty since the check-in. Moreover, any other check-in during this time frame somewhere along this chain resulted in jobs near the end of chain aggregating additional changes from TFS. Consequently, failure notification emails were sent to a group of developers and they were in no hurry to take responsibility for something that was not necessarily their fault.
What do we have now ?
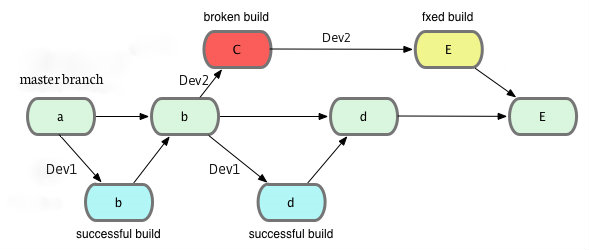
First of all, we put a lot of effort to minimize jobs execution time and right now the longest chain of jobs completes in well under 10 minutes. But after migration to Git a major change was in our new strategy to tackle “broken builds”. Each developer now works on a local branch, pulls from the central repository master branch but pushes back to his/her personal branch. Git Plugin allows Jenkins to merge master branch into this personal branch, run all necessary jobs on it and merge it back to master on success. In case of a failure, the broken branch is ignored, master branch remains untouched. Any pushes made by other developers at the same time are run separately on different branches and don’t affect each other. Feedback on success/failure of the build is sent only to the developer who triggered it, so no more lame excuses.
This concept is not new for CI servers, there is a “Gated Check-in” in TFS or “Delayed Commit” in TeamCity. What makes our approach a bit different is that the process is automated – no need to specify which build definition you want to use for your changes to be built, tested and pushed back to master. We have incorporated logic in Git post-receive hook that inspects the changes made by the developer, identifies and then triggers corresponding job in Jenkins. Another advantage compared to the 2 methods mentioned above is that the branch with broken build can be easily accessed by other developers for review or assistance. In fact, with this approach it can even be more productive to allow a broken build than to try to prevent it all the time.
That’s about it on how we do CI these days.
More from our blog
 Finest Social Local casino 100percent free slot online treasures of egypt Slots & Video game On the web
Finest Social Local casino 100percent free slot online treasures of egypt Slots & Video game On the web Mobile Casinos: Beste Kasino-Ernährer fürs Spielen Sie book of tribes Slot online Taschentelefon 2026
Mobile Casinos: Beste Kasino-Ernährer fürs Spielen Sie book of tribes Slot online Taschentelefon 2026 Get casino zodiac free spins $800 Bonus
Get casino zodiac free spins $800 Bonus mummys silver Casino: Top Because the 2002 which have Quick Earnings deposit 5 get 100 free casino & Simple Mobile Play
mummys silver Casino: Top Because the 2002 which have Quick Earnings deposit 5 get 100 free casino & Simple Mobile Play Best PaysafeCard Gambling enterprises 2026 top online casinos Australia real money Betting with paysafecard
Best PaysafeCard Gambling enterprises 2026 top online casinos Australia real money Betting with paysafecard Angeschlossen Bimbes einbringen: 50 kostenlose Spins keine Einzahlung golden book Kostenlose Methoden
Angeschlossen Bimbes einbringen: 50 kostenlose Spins keine Einzahlung golden book Kostenlose Methoden