
Computer vision application - Challenges of learning ordinary concepts
Basic systems can be created from off the shelf components allowing solving in a relative easy task problems of detection (“what is the object appearing in the image?”), localization (“where in the image there is a specific object?”) or a combination of both.


Above: Two images from the ILSVRC14 Challenge
Most systems capable to create product level accuracies are limited to a fixed set of different predetermined concepts, and are also limited by the inherently assumption that a representing database of all possible appearance of the required concepts can be collected.
The above two limitations should be considered when designing such a system as concepts and physical objects used in everyday life may not be easily fitted to these limitations.
Even though CNN based systems that perform well are quite new, the fundamental questions outlined below relate to many other Computer Vision systems.
One consideration is that some objects may have different functionality (and hence a name) whereas they have the same appearance.
For example, the distinction between a teaspoon, tablespoon, serving spoon, and a statue of a spoon is related to their size and usage context. We should note that in such case the existence and definition of the correct system output is highly depending on the system’s requirements.


In general, plastic artistic creations, raises the philosophical question of what is the shown object (and hence the required system’s output). For example – is there a pipe shown in the below image?
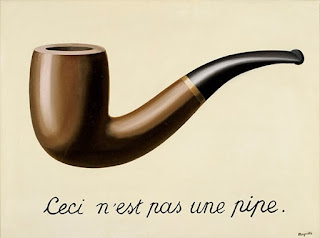
When defining a system to recognize an object, another issue is the definition of the required object. Even for a simple daily object, different definitions will result in different set of concepts. For example, considering a tomato, one may ask what appearances of a tomato are required to be identified as a tomato.
Clearly, this is a tomato:
But what about the following? When does the tomato cease to be a tomato and becomes a sauce? Does it always turns to a sauce?



Since this kind of Machine Learning systems learns from examples, different systems will behave differently. One may use all examples of all states of a tomato as one concept, whereas another may split it to different concepts (that is, whole tomato, half a tomato, rotten tomato, etc.). In both cases, tomato that has a different appearance and is not included in none of the concepts (say, shredded tomato) will not be recognized.
Other daily concepts have a meaning functional (i.e. defined by the question “what is it used for?”) whereas the visual cues may be limited. For example, all of the objects below are belts. Except for the typical possible context (possible location around the human body, below the hips) and/ or functional (can hold a garment), there is no typical visual shape. We may define different types of belts that interest us, but then we may need to handle cases of objects which are similar to two types and distinctively belongs to one type.



Other concept definition considerations that should be addressed may be:



Written by Yohai Devir.
More from our blog
 My Twin Celeb, Facial Recognition Tech, Oh My!
My Twin Celeb, Facial Recognition Tech, Oh My! BetMGM Game Personal: Star Trek: The new generation volcano riches game Opinion BetMGM
BetMGM Game Personal: Star Trek: The new generation volcano riches game Opinion BetMGM The storyline Behind typically the most spinsy welcome bonus popular Pokie around australia Conformity Costs & Just what Punters Should become aware of Heat To your Solutions
The storyline Behind typically the most spinsy welcome bonus popular Pokie around australia Conformity Costs & Just what Punters Should become aware of Heat To your Solutions Scorching site neteller 10 dollar casino oficial din Romania
Scorching site neteller 10 dollar casino oficial din Romania A lot more online casino no deposit bonus 30 free spins Cycles and you will Modern Jackpots: Lobstermania for fun
A lot more online casino no deposit bonus 30 free spins Cycles and you will Modern Jackpots: Lobstermania for fun Rabbit Win Casino UK: A Comprehensive Review for UK Players
Rabbit Win Casino UK: A Comprehensive Review for UK Players